시작하기
남은 연말 기간동안 간단한 토이 프로젝트를 진행해보기로 했다. 목표는 다음과 같다.
- CGV에서 상영중인 영화 데이터를 크롤링해오는 코드를 작성하기
- 해당 데이터를 매일 Slack 채널에 전달하는 챗봇 구현
- RSS를 구독하듯 영화관에서 상영중인 영화 정보를 매일 보내준다.
- 이와는 별개로 영화관/영화/날짜 정도로 검색할 수 있는 기능도 구현한다.
- 코드가 돌아가는 서버가 필요할 것 같다. 가지고 있는 라즈베리파이나 GCP를 이용하면 될 것 같다.
- 챗봇에 포함된 링크를 통해서 바로 예매 페이지로 들어갈 수 있도록 하는 것이 목표
지금은 우선 가장 중요한 기능만 우선적으로 구현해보도록 하겠다.
영화 데이터 크롤링
위의 목표를 순차적으로 달성하기 위해 우선 cgv 사이트에서 영화 데이터를 크롤링해올 수 있는지 최대한 간단한 구현을 통해 확인해보았다. 여기까지는 충분한 레퍼런스가 있었다. 슬랙과 연동하는게 어려운 부분이 될 것 같다.
CGV 사이트의 쿼리 규칙
http://www.cgv.co.kr/common/showtimes/iframeTheater.aspx?theatercode={}&date={}
2개의 query 정보를 통해서 해당 상영관의 상영 시간표를 받아올 수 있다.
- theatercode: 상영관 코드, CGV 상영관별로 코드가 다르다. 여기에 특별한 규칙은 없는 것 같아서 따로 리스트를 만들거나 해야 할 듯. 우선 내가 자주 방문하는 용산아이파크몰의 경우에는 코드가 0013이었다.
- date: YYYYMMDD 형태.
예를 들어 http://www.cgv.co.kr/common/showtimes/iframeTheater.aspx?theatercode=0013&date=20220101 의 주소로 접속한다면 CGV 용산아이파크몰의 2022년 1월 1일 상영시간표를 확인해볼 수 있다.
BeautifulSoup를 사용한 크롤링
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from pyprnt import prnt
import requests
from bs4 import BeautifulSoup
def get_theater_code_from_name(theater_name:str):
raise NotImplementedError
def get_url_with_query(theater_code:str, date:str):
base_url = 'http://www.cgv.co.kr/common/showtimes/iframeTheater.aspx?theatercode={}&date={}'
return base_url.format(theater_code, date)
def get_soup(url):
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
return soup
get_theater_code_from_name()의 경우에는 앞서 살펴봤듯이 당장 상영관 코드에 규칙이 없고 직접 수집해야 할 것으로 보이기 때문에 우선순위를 낮추고 구현을 보류했다. 지금 당장은 용산아이파크몰의 데이터를 크롤링하는 것을 기준으로 진행하기로 했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
def clean_text(text):
text = text.replace('\n', '')
text = text.replace(' ', '')
text = text.replace('\r', '')
text = text.replace('총', '')
return text
def get_movie_info(soup):
movies = soup.select('body > div > div.sect-showtimes > ul > li')
data_dict_list = []
for each_movie in movies:
title = each_movie.select_one('div.info-movie > a > strong').text.strip()
data_dict = {}
hall_info = each_movie.select('div.type-hall > div.info-hall > ul')
hall_info_list = []
for each_hall_info in hall_info:
each_hall_info_dict = {}
each_hall_info_dict['hall_type'] = clean_text(each_hall_info.select('li')[0].text)
each_hall_info_dict['hall_name'] = clean_text(each_hall_info.select('li')[1].text)
each_hall_info_dict['hall_total_seat'] = clean_text(each_hall_info.select('li')[2].text)
hall_info_list.append(each_hall_info_dict)
timetable_info = each_movie.select('div.type-hall > div.info-timetable > ul')
timetable_info_list = []
for each_timetable_info in timetable_info:
each_time_list = []
for each_time in each_timetable_info.select('li'):
text = each_time.text.replace('잔여좌석', '')
try:
link = 'https://www.cgv.co.kr' + each_time.find('a')['href']
except:
link = None
each_time_list.append([text[0:5], text[5:], link])
timetable_info_list.append(each_time_list)
data_dict['movie_title'] = title
data_dict['hall_list'] = hall_info_list
for i in range(len(hall_info_list)):
data_dict['hall_list'][i]['timetable'] = timetable_info_list[i]
data_dict_list.append(data_dict)
return data_dict_list
데이터를 정제해서 딕셔너리 형태로 만들어 반환하는 함수를 구현했다. 각각의 영화에 대해서 제목, 상영관의 정보(종류, 이름, 총 좌석수), 상영시간표(상영시간, 잔여좌석, 예매 페이지로 연결되는 링크)를 저장하도록 했다.
1
2
3
4
5
6
7
8
9
10
if __name__ == '__main__':
#theater_name = '용산아이파크몰'
#theater_code = get_theater_code_from_name(theater_name)
theater_code = '0013'
date = '20220101'
url = get_url_with_query(theater_code, date)
soup = get_soup(url)
data_dict_list = get_movie_info(soup)
prnt(data_dict_list)
실행 결과
그냥 출력해서는 도저히 시각화가 안 되기 때문에 pyprnt 패키지를 통해서 출력 결과를 확인하고, 웹사이트의 결과와 비교해 보았다.
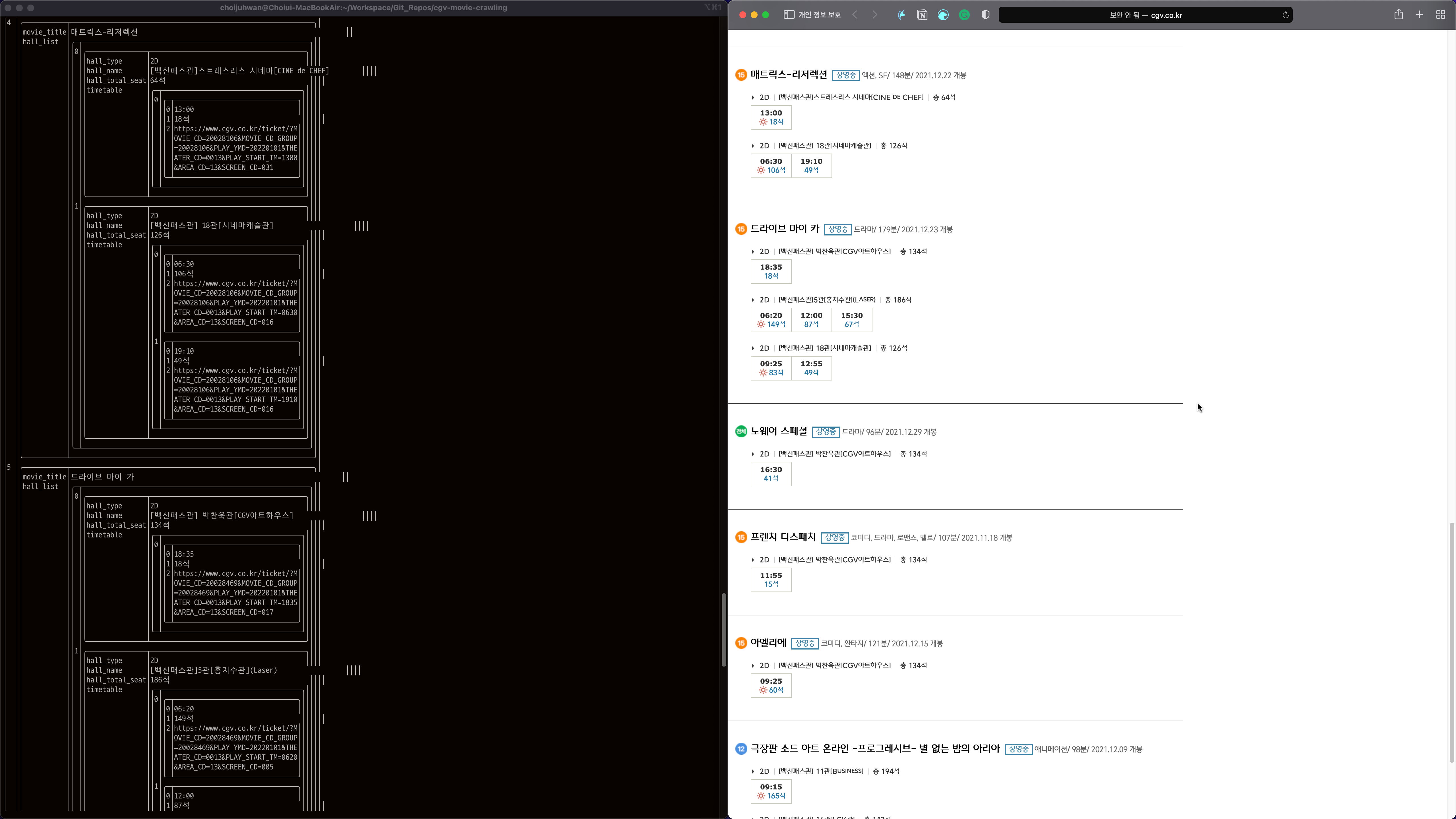
정상적으로 데이터를 확보했음을 확인할 수 있다!
다음 목표
- 영화관 이름과 영화관 코드 데이터를 확보 후 매칭
- 영화관 이름을 대략적으로 입력하더라도 영화관 코드를 알 수 있도록 하기 -> 검색 기능 구현
- 슬랙봇을 제작해서 연동