개요
Yann Lecun 등이 2015년에 Nature에 게재한 Deep learning. Deep learning이 어떻게 이루어지는지 잘 설명되어 있다고 생각해서, 처음으로 읽어보고 정리해보기에 가장 좋을 것이라고 판단했다.
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
https://doi.org/10.1038/nature14539
Abstract
딥 러닝은 복수의 처리 계층으로 구성된 계산 모델이 다층으로 추상화된 데이터 표현을 배울 수 있도록 한다. 이러한 방법은 음성 인식, 시각적 물체 인식, 물체 탐지, 약물 발견과 유전학까지의 영역에서 최고점(state-of-the-art)를 극적으로 끌어올렸다. 딥 러닝은 Backpropagation을 통해 거대한 데이터셋에서 복잡한 구조를 발견한다. Backpropagation은 이전 Layer에서 다음 Layer로 넘어가는데 사용되는 Parameter를 어떻게, 얼마나 변경해야 하는지 확인하는 방법이다. Deep convolutional net (CNN)은 이미지, 비디오, 음성 처리에 혁명적인 결과를 이룩했으며, Recurrent net (RNN)은 텍스트와 스피치 등 순차적 데이터 처리에 발전을 가져왔다.
Machine Learning
기존의 Machine Learning에 한계점이 있었음을 지적한다. 그 한계점이란 우리가 가지고 있는 데이터를 학습 알고리즘의 형식에 맞게 수정해 주어야 한다는 것.
즉, 알고리즘이 이미지 패턴을 구별하는 등의 역할을 하도록 하기 위해서는 이미지 픽셀 데이터를 그에 맞는 형태로 수정해주는 등의 작업이 필요하다는 지적이다.
Representation Learning은 이와 달리, 알고리즘이 데이터를 그대로 입력받고, 자동적으로 탐지나 분류에 필요한 표현을 찾아낸다. 전통적인 기법과 달리 데이터를 수정해줄 필요가 없다는 것.
딥 러닝은 이러한 Representation Learning을 여러 단계로 진행하는 것을 말한다. 한 단계의 표현을 비선형 함수 모듈을 통해 더욱 추상화된 다음 단계 표현으로 변환시킨다.
아래 이미지를 보면 조금 더 이해가 될 것이다. 왼쪽 낮은 단게에서는 단순히 선과 원이 보일 뿐이다. 그러나 다음 Layer로 넘어가면서 점점 더 추상적인 부분을 인식, 결과적으로 물체를 인식할 수 있게 된다.
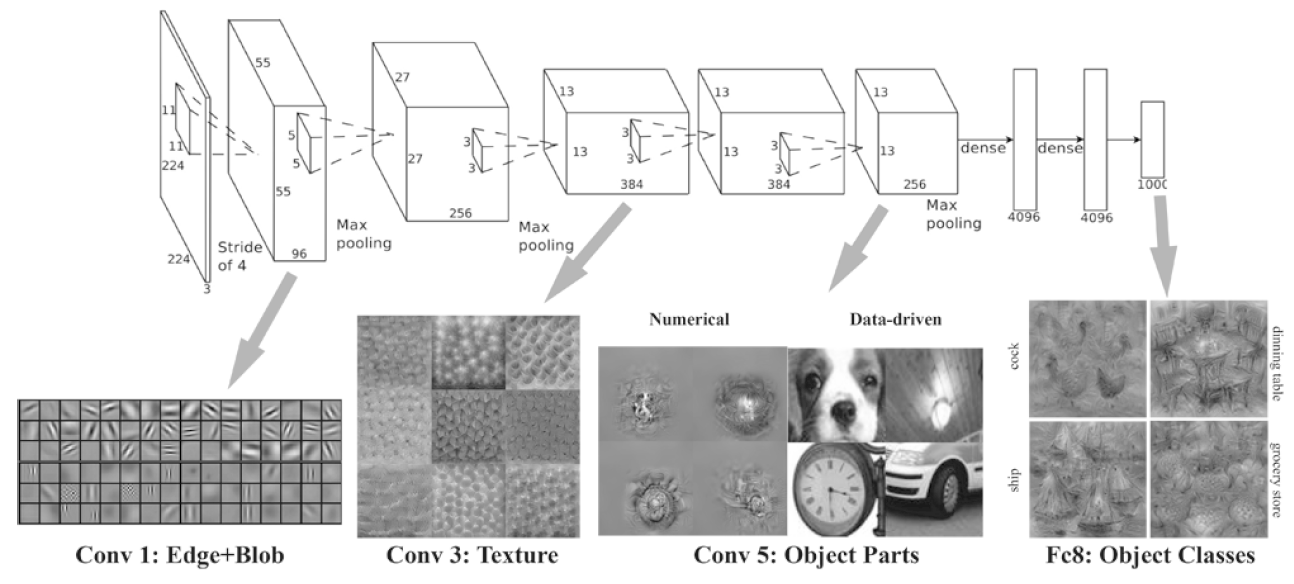 From https://velog.io/@dscwinterstudy/2020-01-28-1501-작성됨-8zk5xihhpz
From https://velog.io/@dscwinterstudy/2020-01-28-1501-작성됨-8zk5xihhpz
딥 러닝의 핵심은 이런 Layer를 사람이 만들어 주어야 하는 것이 아니라, 일반적인 학습 과정을 통해 Data에서 스스로 배워나간다는 점이다. 사람이 실제로 신경써야 할 것은 많지 않기 때문에, 데이터와 계산 능력이 늘어난다면 그 효과를 쉽게 체감할 수 있다.
Supervised Learning
꼭 딥 러닝이 아니더라도, 머신러닝의 가장 일반적인 형태는 지도 학습(Supervised Learning)이다. 지도 학습은 Data로서 Input과 그에 따른 Output을 한 쌍으로 사용한다.
Input Data(이미지 분류 문제라면, 이미지 데이터)를 입력받은 뒤, 출력된 각 카테고리에 속할 확률 벡터를 (주어진 이미지가 강아지일 확률 85%, 늑대일 확률 10%, 고양이일 확률 5% 등) 우리가 알고 있는 정답과 비교한다.
우리의 목표는 강아지 사진을 넣으면 강아지일 확률이 가장 높은 모델을 설계하는 것이다. 그러나 당연히 학습이 이루어지기 전에는 불가능한 일일 것이다.
모델을 학습시키기 위해서 주어진 정답과 도출한 결과 간의 오차를 측정하는 목적 함수를 사용한다. 이 오차를 바탕으로 모델 내부의 Weight, 즉 가중치를 변경한다.
최근에는 Loss function, 오차 함수라는 말이 더 흔한 것 같은데 이 논문에서는 Objective function이라는 단어를 쓰고 있다.
가중치를 올바르게 조정하기 위해서, 학습 알고리즘이 기울기 벡터를 계산해낸다. 기울기 벡터는 각각의 가중치가 약간씩 변경된다면, 전체 오차에 어떠한 영향을 미치는지를 나타낸다. 기울기 벡터의 반대 방향으로 가중치를 조절함으로서, 오차를 줄여나갈 수 있다.
기울기 벡터 (Gradient)란 아래 그림을 보면 이해가 빠르다. 검은색이 높은 값을 가진다고 보았을 때, 푸른 화살표들은 높은 값으로 향하는 방향을 가리키고 있다. 이 화살표들이 Gradient인데, 그렇다면 화살표의 반대 방향은 값이 작아지는 방향이라고 볼 수 있겠다. 목적 함수에 대해서 Gradient를 계산하면, Gradient가 가리키는 방향의 반대 방향이 오차가 작아지는 방향인 것이다.
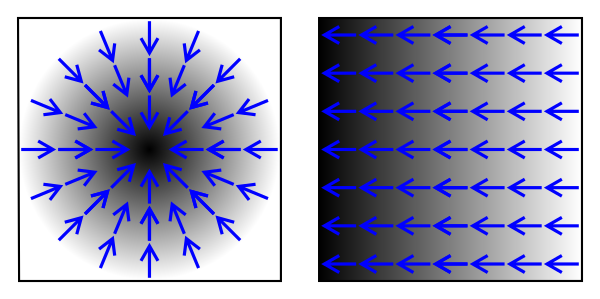 From https://en.wikipedia.org/wiki/Gradient
From https://en.wikipedia.org/wiki/Gradient
다음으로 논문은 SGD(Stochastic Gradient Descent)를 소개한다. 딥 러닝의 특성 상 Input이 너무 많기 때문에 이것들 전부에 대해서 오차를 계산한다면 너무 많은 시간이 걸린다. SGD에서는 전체 데이터 중 일부만 랜덤하게 골라서 결과값을 도출하고, 오차를 계산한다. 그리고 Gradient의 평균값을 내어서 가중치를 조절하는데 이용하는 방식이다.
이 과정을 목적 함수의 평균값이 더 이상 감소하지 않을 때까지 반복한다. (각 반복 시 마다 사용하는 데이터는 계속 랜덤하게 새로 뽑는다.)
이런 방식으로 학습을 진행하여 모델에게 주어진 역할에 맞는 적절한 가중치를 찾아낼 수 있다.
논문에서는 이 방법만을 학습 방법으로 설명하고 있는데, 2015년에서 5년이 넘게 지난 지금은 Adam 등 다양한 학습 방법이 있다. 나중에 기회가 되면 그 논문들도 읽고 정리해보려고 한다.
이렇게 학습을 마친 뒤에는, 학습에 사용하지 않았던 데이터를 통해서 (즉, 모델 입장에서는 본 적 없던 새로운 데이터이다) 모델의 성능을 평가한다.
일반적 Machine Learning과 Deep Learning의 차이
현재 머신러닝 기법을 적용한 케이스 중 대다수는 Linear classifier를 사용하고 있다. 입력으로 주어진 Feature vector의 Weighted sum (가중치를 곱해서 합한 것)을 구해서, 이 합이 Threshold (문턱 등을 의미하는데, 여기서는 기준값 정도로 이해하면 될 것 같다)를 초과하면 특정 카테고리에 속하는 것으로 분류한다.
Linear classifer, 즉 선형 분류라는 이름에 맞게 이 시스템은 입력된 데이터를 상당히 단순한 형태로만 분류할 수 있다. 그런데 이미지나 음성을 인식하는 것은 이런 단순한 구조로는 쉽지 않은 문제이다.
논문은 개와 늑대를 구별하는 경우를 예시로 들고 있다. 예를 들어 주어진 이미지를 제대로 인식해서 분류하고자 한다면 개나 늑대가 어떤 자세나 각도로 찍힌 사진인지와 무관하게 인식할 수 있어야 할 것이다. (즉, 입력에서 중요하지 않은 특징은 무시할 수 있어야 한다.) 마찬가지로 정말 중요한 특징은 확실하게 구별할 수 있어야 할 것이다.
좀 더 상세하게, 털이 하얀 사모예드와 흰 늑대를 분류해야 한다고 가정해 보자. 사모예드와 늑대를 같은 자세로 찍었다면 정말 비슷한 사진이겠지만, 그럼에도 둘을 확실히 구별할 수 있어야 하는 것이다. 또한, 사모예드를 서로 다른 각도에서 찍었다면 픽셀값이라는 측면에서는 정말 다른 사진이겠지만, 그럼에도 같은 사모예드로 분류할 수 있어야 한다.
선형 분류처럼 ‘얕은’ 분류 방식은 픽셀 단위에서만 작동하는데, 이런 구조로는 사모예드와 늑대를 제대로 구별하기 어렵다. 아마 앞서 같은 자세로 찍은 둘의 사진을 제대로 구별하기 못하고 한쪽으로 합쳐버릴 것이다.
이런 이유로 인해서 우리가 가지고 있는 데이터를 학습 알고리즘의 형식에 맞게 수정해 주어야 한다는 한계점이 있다고 앞서 지적한 것이다. (Selectivity-Invariance Dilemma) 선형 분류 구조가 제대로 둘을 구별할 수 있도록 하기 위해서는, 사람이 사진 속 픽셀 데이터에서 구별에 중요한 특징을 추출하고 중요하지 않은 특징은 무시하는 작업이 필요하다.
그렇지만 이런 작업을 자동적으로 진행할 수 있다면? 그것이 바로 딥 러닝이다.
딥 러닝 구조는 단순한 학습 레이어를 다층으로 쌓은 구조인데, 이 레이어가 입력을 비선형적인 출력으로 변환한다. 각각의 레이어가 중요한 부분은 점점 강조하고, 중요하지 않은 부분은 점점 무시하기에 이를 다층 (5~20층)으로 쌓는다면 사모예드와 늑대를 구별하는 데 핵심적인 특징에는 민감하게 반응하고, 배경이 어떤 곳인지와 같이 중요하지 않은 특징에는 민감하지 않은 구조를 완성할 수 있다.
Backpropagation to train multilayer architectures
앞서 언급했듯이 Backpropagation을 통해서 목적 함수의 기울기 벡터를 계산하고 결과적으로 모델의 가중치를 수정한다. 이 Backpropagation은 고등학교 미적분 시간에 배우는 Chain Rule (연쇄 법칙)을 적용한 것이다.
핵심은, 모델 끝에 있는 목적 함수의 Input에 대한 기울기를 구하기 위해서 목적 함수에서부터 역순으로 계산을 취할 수 있다는 것이다. 아래 그림에서 x를 Input으로, y를 Hidden Layer로, z를 Output으로 생각해 보자. x → y → z 순으로 계산이 이루어진 뒤, x에 대한 z의 변화량을 구하기 위해서는 다음과 같은 과정을 취한다.
- y에 대한 z의 변화량을 구한다.
- x에 대한 y의 변화량을 구한다.
- 1과 2를 결합함으로써, x에 대한 z의 변화량을 구할 수 있다.
이것이 아래 그림이 의미하는 바이다.
중간에 단계가 더 추가되더라도 (즉 더 많은 Layer를 쌓더라도) 이와 같은 과정을 통해서 Input에 대한 Objective function의 기울기를 알 수 있다.
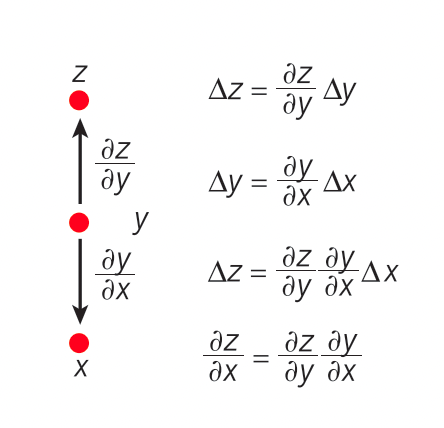 From the paper
From the paper
학습 과정에서 한 Layer에서 다음 Layer로 넘어가는 순전파(Forward propagation)에는 비선형 함수 (Nonlinear function)가 사용된다. 대표적으로는 다음과 같은 것이 있다.
- ReLU: f(z) = max(0, z)
- Sigmoid: f(z) = 1/(1+exp(-z))
- Tanh(z)
ReLU를 말로 풀어서 설명하면 아래와 같다.
z =< 0일때 0, z > 0일때 z
90년대까지는 이러한 학습 방법이 Poor local minima에 빠져버릴 것이라고 생각되었다. 이 방법을 가만 지켜보면 ‘기울기를 따라서 내려간다’는 것이 핵심인데, 그렇게 내려가는 도중 진짜 최소값이 아니라 극소값에서 멈춰버리는 것이 아니냐는 지적이 있었다는 것.
그러나 논문은 이러한 문제가 딥 러닝을 대규모로 진행하는 과정에서는 큰 문제가 아니라고 설명한다.
Convolutional neural networks
Convolution은 한국어로 합성곱이라고 한다. 곱한 것을 더한다는 의미를 담고 있다. 수학적으로는 두 함수 중 하나를 뒤집은 뒤 곱해가면서 적분하는… 뭐 그런 연산이지만 생략해도 좋을 것 같다. 중요한 것은 곱해서 더한다는 사실이라고 생각한다.
Convolutional neural network, CNN은 다차원적으로 구성된 데이터를 처리하기 위해 등장했다. 대표적으로 이미지 인식에 주로 사용되는데, 이는 이미지가 2차원 데이터임을 생각해보면 이해가 쉽다.
CNN에는 두가지 종류의 Layer가 있다.
Convolution Layer는 Feature map으로 구성되어 있어서, 특징을 추출해내는 단계이다. Pooling Layer는 특징을 압축하는 단계라고 볼 수 있다. 이렇게 함으로서 찾아내야할 특징의 위치나 모양이 약간 바뀐다고 하더라도 문제 없이 특징을 검출해낼 수 있다.
위와 같은 Layer를 여러 단계 거친 결과물을 통해서 이미지를 분류하는 등의 역할을 할 수 있다.
CNN은 이렇게 짧게 다루기에는 너무 중요하다고 생각해서, 나중에 기회가 되면 따로 포스팅하려고 한다.
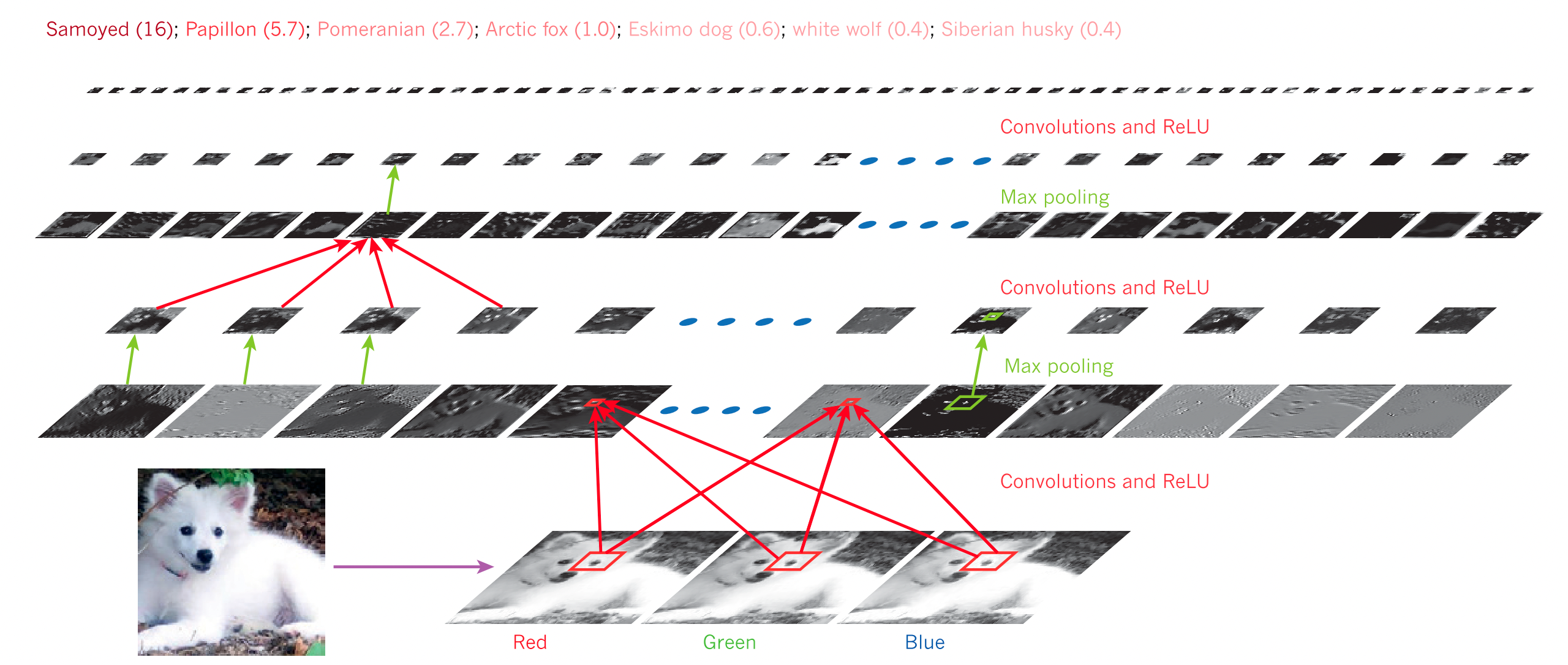 From the paper
From the paper
Distributed representations and language processing
주어진 여러 단어가 문장 속에서 사용되는 용례를 통해서 딥 러닝 모델이 단어 간의 관계를 찾아내는 과정을 보여주고 있는데, 이건 NLP 개념에 대한 설명도 많이 들어갈 것 같고 해서 따로 쓸 생각이다.
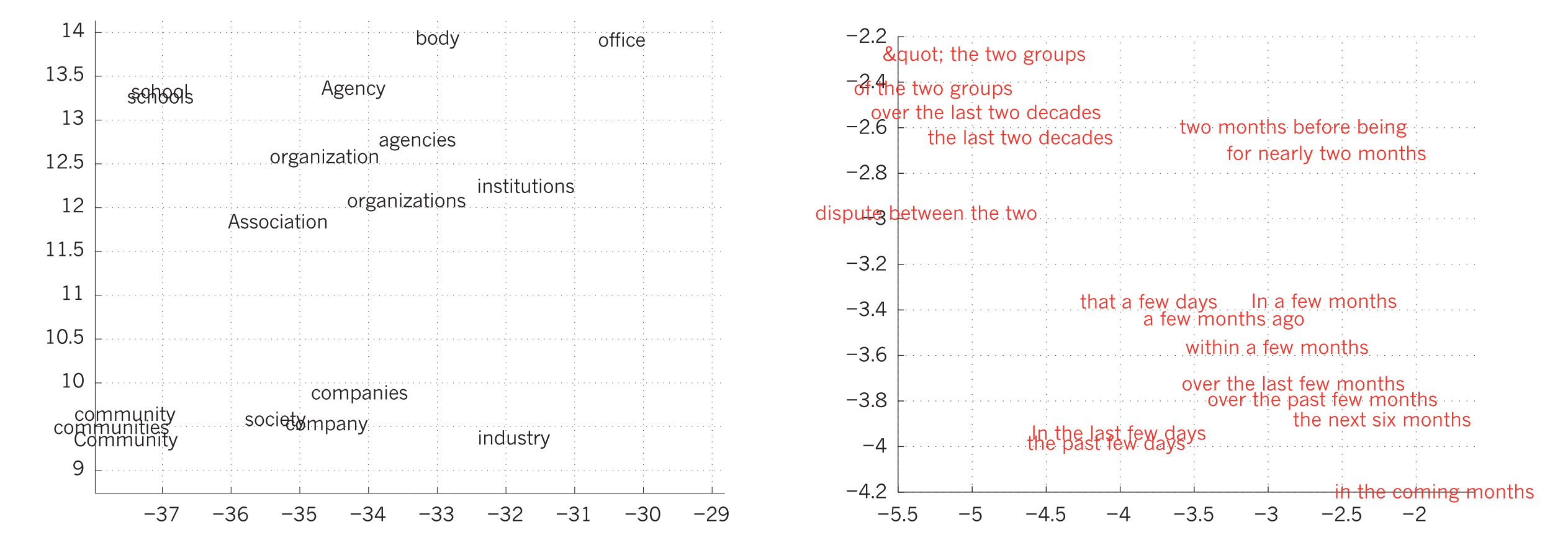 From the paper
From the paper
여기서는 어떤 결과가 나타나는지만 그림을 통해 짚고 넘어가겠다.
특히 오른쪽 ‘In the last few days’와 ‘the past few days’가 거의 같은 위치에 존재하는데, 실제로 둘의 의미가 유사함을 생각해보면 이 모델이 어떤 역할을 했는지 이해할 수 있을 것이다.
Recurrent neural networks
RNN은 순차적인 입력, 예를 들어서 사람의 대화나 언어를 처리하는데 특화되어 있다.
받은 입력을 바로 Output으로 내놓는 것이 아니라 그것을 내부의 ‘Hidden State’에 저장하고, 그 Hidden State에서 Output을 내놓는다. 결과적으로 Hidden State에는 지금까지의 모든 Input이 저장되어 있다.
RNN에 대해서도 따로 다루려고 한다.
The future of deep learning
논문에서는 사람과 동물이 학습하는 과정이 Unsupervised, 즉 정답을 제공하지 않아도 스스로 관찰을 통해 학습하는 방식이기에 Unsupervised learning의 중요성이 앞으로 더욱 커져갈 것으로 보고 있다.
자연어 처리에도 딥 러닝이 큰 효과를 거둘 것으로 보고 있는데, RNN을 통해 문장이나 문서 전체를 이해하는 시스템을 예로 들고 있다.
정리하고 느낀 점
처음으로 논문을 읽어 보고 또 정리해 봤는데, 단순히 읽기만 하는 것과는 난이도가 달랐던 것 같다. 최대한 핵심만 짧게 쓰려고 하다 보니 빼먹은 부분이 많은데, 그런 부분은 나중에 블로그에 하나씩 따로 쓸 생각이다.