개요
NLP의 각 분야와 발전 방향에 대해서 소개하는 논문.
Hirschberg, J. & Manning, C. D. Advances in natural language processing. Science 349, 261–266 (2015).
https://science.sciencemag.org/content/349/6245/261
Abstract
자연어처리는 인간의 언어를 학습, 이해, 생성하는데 전산 기술을 이용한다. 언어 연구 분야에서 초기에 있었던 전산적 접근은 언어의 언어학적 구조를 자동적으로 분석하고 기계 번역, 음성 인식, 음성 생성 등의 기초 기술을 개발하는데 초점을 두었다. 오늘날 연구자들은 이러한 도구를 개선하고, 또 이를 음성 대화 시스템, 음성-음성 번역 엔진, 건강 또는 금융에 대한 정보 수집 목적의 SNS 데이터 마이닝, 제품 및 서비스에 대한 감정 식별 등 현실 세계에 적용하고 있다. 이 논문은 빠르게 발전하고 있는 이 분야의 성공과 도전과제에 대해서 설명한다.
NLP의 발전 역사
전산언어학, 즉 NLP는 컴퓨터과학의 하위분야로서 전산적 접근을 통해 언어를 이해하고 학습하며, 문장 등을 생성하기도 한다. 기계번역 등 사람과 사람 간의 소통을 도울 수도 있고, 챗봇 등 사람과 기계 간의 소통을 원활하게 하는데도 활용할 수 있다.
이 분야는 지난 20년 동안 흥미로운 연구 분야 및 구글 번역기부터 챗봇까지 소비자 제품에 적용되는 기술으로서 성장했다.
논문은 이러한 발전의 원인으로 네가지를 언급한다.
- 컴퓨터 계산 성능의 폭발적 증가
- 대량의 언어 데이터 확보
- 머신러닝 기법의 발전
- 인간 언어 구조에 대한 이해가 깊어졌음
과거에는 과학자들이 컴퓨터에 사람이 사용하는 언어의 규칙과 단어를 모두 입력시키고자 했다.
그렇지만 사람의 언어는 그러한 방식으로 분석하기에는 상당히 모호하고, 불명확한 측면이 크다. 한국어에서도 ‘눈’은 시각을 담당하는 신체의 기관이기도 하지만, 겨울에 일어나는 자연현상을 뜻하기도 한다. 논문에서는 ‘Star’가 천체일수도 있지만, 인기가 많은 사람을 지칭하는데 사용될 수도 있음을 지적한다. 게다가, 하나의 문장을 여러가지 의미로 해석하는것도 가능한 경우도 있다. 이러한 이유에서 초창기 시도는 좋은 성능을 보여주지 못했다.
80~90년대에 들어, 대량의 데이터를 기반으로 모델을 구축하고자 하는 시도가 일어났다. 이렇게 등장한 통계 및 Corpus 기반 NLP가 빅데이터 사용의 최초 성공 사례 중 하나라고 이야기한다. 이 과정에서 발견된 사실은 단순한 방법이라고 하더라도 대량의 데이터를 통해 학습한다면 유의미한 성과를 거둘 수 있다는 것이다.
한편 최근 가장 성능이 좋은 시스템은 머신러닝을 이용하고 있다. 논문에서는 이러한 시스템의 예시로 Stanford CoreNLP를 보여주고 있다.
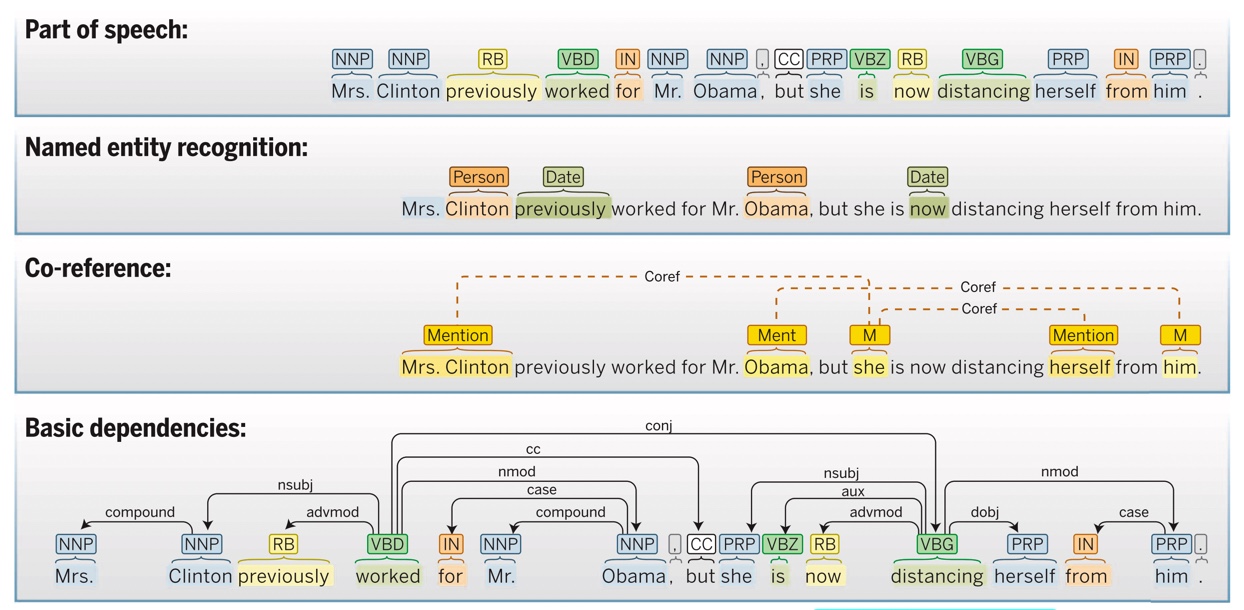
위 그림을 통해 알 수 있듯이
- 문장의 품사 분석
- NNP, RB 등 태그에 대한 자세한 내용은 https://m.blog.naver.com/bycho211/221893460325를 참고.
- 의미 분석
- Clinton은 사람, now는 시간의 의미를 가짐을 분석하고 있다.
- 언급 관계 분석
- Mrs. Clinton이 she, herself와 같은 인물임을 분석한다.
- 문법적 관계 분석
등을 해내고 있다.
이렇게 NLP를 빅데이터라는 분야에 접목시킬 수 있었던 데는 두가지 요인이 있다고 한다. 첫번째로는 연구자들이 빠르게 디지털화된 언어 데이터를 이용할 수 있었던 점, 그리고 두번째로는 마치 Kaggle이 오늘날 그러하듯이 경쟁을 통해 성능을 향상시켰다는 점을 들고 있다.
Kaggle은 일종의 머신러닝 경진대회 사이트이다. 머신러닝 및 딥러닝에 이용해볼 수 있는 다양한 자료가 올라오고, 이를 다운로드받아 공부하는 데 사용하거나 Competition을 통해 타인과 스코어를 겨뤄볼 수 있다.
현재 시점 에서 NLP의 한계점은 대부분의 NLP 시스템이 사용자가 많은 언어에만 적용된다는 것이다. 정확히는 자료가 많고 수요가 많은 언어. 그렇지 못한 언어의 경우에는 자료도 부족하고 수요도 부족하기에 이런 시스템이 개발되지 못한다.
앞으로의 도전과제는 이렇게 자료가 적은 수천개의 언어에 대한 자료와 도구를 개발하는 것이 될 것이다.
Machine translation
요즘은 구글 번역이나 네이버 파파고 덕분에 서로가 상대방의 언어를 잘 몰라도 어느 정도 소통이 가능한 시대다. 이렇게 기계 번역은 컴퓨터가 사람 간의 소통을 도와주는 대표적 사례다.
기계 번역 시스템이 정확한 번역을 하기 위해서는 크게 두가지가 필요하다.
- 사람의 언어를 분석 및 이해하고, 생성하는 능력
- 사람처럼 문장의 맥락을 이해하는 능력
- 즉 앞서 언급된 언어의 모호성을 감안할 수 있는 능력
기계 번역은 수치를 계산하지 않는 분야에 컴퓨터를 사용한 최초의 사례 중 하나이다. 1950년대 후반부터 시도가 있었는데 이는 문법적 규칙을 직접 하나하나 다 입력하는 방식이었고, 그다지 성공적이지는 못했다고 한다.
90년대 초반에 들어서 IBM에서 영어-프랑스어 간 일종의 로제타석같은 데이터를 구축했다. 이러한 데이터셋에 기반하여 확률적 모델이 도입되었다.
90년대 후반에는 단어를 일대일로 번역하는 것이 아니라, 몇몇 단어를 묶어서 하나의 구(Phrase)를 번역하는 아이디어가 등장했다.
최근에는 딥러닝 기반 모델이 도입되어 큰 성능 향상을 보여주고 있다. 번역 성능을 높이는 것을 목표로 하는 모델을 구축하여, 모델이 스스로 학습하게 하는 것이 핵심이다. 번역에는 특히 RNN(Recurrent Neural Network)의 개량형인 LSTM(Long Short-Term Memory)이 사용된다.
Spoken dialogue systems and conversational agents
‘대화’라는 주제는 1980년대부터 NLP 분야에서 인기 있는 주제였다고 한다. 초창기에는 단순히 텍스트 기반 대화였지만, 지금은 음성 언어로 대화할 수 있을 정도로 발전했다. (Siri, Alexa, Cortana 등등)
음성 대화 시스템 (Spoken Dialogue System)은 로봇이 사람의 작업을 돕거나, 심리상담, 인터뷰 및 협상을 가르치는 데 사용되는 등 다양한 역할을 할 수 있다.
이러한 음성 대화 시스템을 구축하는 데에는 몇가지 구성요소가 필요하다.
- 자동적으로 음성을 인식하여 사람이 말하는 내용을 판별
- 대화 관리 (Dialogue Management)를 통해 사람이 무엇을 원하고 있는지 판단
- 제공할 정보의 습득 및 사람이 요청한 작업을 수행할 수 있어야 함
- 정보를 음성의 형태로 돌려주기 위해서 (즉, 대답하기 위해서) Text-to-Speech가 필요
고전적인 음성 인식 방식을 딥러닝으로 대체하는 과정에서 음성 인식의 정확도가 크게 향상되었는데, 실용적인 음성 대화 시스템은 이로 인해서 탄생할 수 있었다.
현재 음성 대화 시스템은 대화의 주제가 정해져 있는 경우에는 잘 작동하지만, 정해지지 않은 주제에 대해서 자유롭게 대화하는 경우에는 성능이 만족스럽지 못하다.
음성 대화 시스템을 구축하는 데에는 많은 과제가 남아 있다. 핵심적인 문제는 앞서 언급된 음성 인식, 대화 관리, TTS의 정확도를 높이는 데 있으며, 다룰 수 있는 주제를 넓히는 것도 중요한 문제이다.
또다른 문제는 사람처럼 자연스러운 대화가 필요하다는 것이다. 인식의 속도가 빨라서 사람만큼 자연스러워야 하며, 대화 과정에서 ‘음…’ 같은 것도 적당히 끼워넣을 수 있어야 한다는 것.
또한 사람은 상대방과 대화가 잘 될때 발음, 표정, 제스처 등을 닮아가는 경향이 있는데 음성 대화 시스템 역시 이렇게 이용자와 대화하는 과정에서 사용하는 단어 등을 비슷하게 변화시켜 나가야 더욱 자연스러운 대화가 가능하다고 여겨진다.
Machine reading
기계 독해는 기계가 지능적으로 사람을 위해서 대량의 텍스트를 읽고 이해해 정보를 합치고, 또 요약하는 분야이다.
인공지능 기술의 초기에는 대다수 연구자들이 구조화된 지식 데이터베이스를 구축하여 여기에서 정보를 도출해내는 방법으로 기계에 지능을 부여하고자 노력했다.
그런데 현재 우리는 위키피디아 등 온라인에 엄청난 양의 정보를 가지고 있다. 특히 과학 분야의 정보가 지수적으로 증가하고 있고, 과학자들이 이를 따라갈 수가 없다. 이러한 상황에서 정보를 이해하고 요약해서 사람에게 제공할 수 있는 기계 독해 시스템의 중요성이 커졌다.
Mining social match
통계 및 머신러닝 기법을 이용한 SNS 상의 텍스트 데이터를 분석을 통해서 마케팅 등에 큰 효과를 발휘할 수 있다는 내용. 그러나 개인정보 이슈가 중요한 문제임을 강조한다.
Analysis and generation of speaker statements
문서에서 감정을 분석하는 내용.
아래 그림 좌측은 Sentiment analysis, 우측은 Emotion analysis이다.

우선 좌측의 Sentiment analysis부터 보자면, 주어진 문서에서 각 문장을 긍정적/부정적/중립적 세가지로 분류하고 있다. 이는 문장 내에서 긍정적인 의미, 혹은 부정적인 의미를 담고 있는 단어를 통해서 유추해낼 수 있다. 이 예시에서는 ‘terrible’ 등이 그러하다.
우측의 Emotion analysis는 긍정적/부정적/중립적이라는 3가지 분류에서 조금 더 나아가서, 폴 에크만이 주장한 6가지 기본 감정(행복, 슬픔, 분노, 놀람, 공포, 혐오)을 찾아내는 것을 목표로 한다.
영화나 제품 리뷰를 분석하는 등의 업무에 유용하게 사용될 수 있겠다.
Conclusion and outlook
지난 50년간 열정적인 연구자들은 SF 소설과 영화와 같은 언어 이해 능력을 희망했다. 그러나 그동안은 기대만큼 좋은 결과가 나오지 못했다.
이런 상황은 지난 5년간 급격히 변화했다. 음성 인식 기술의 발전으로 핸드폰에 대고 말하는 것은 자연스러운 일이 되었고, 검색 엔진 기술의 성장으로 복잡한 검색어도 능숙하게 처리할 수 있다. 또한 기계 번역 역시 발전을 거듭하여, 전혀 모르는 언어라고 할지라도 어떤 의미인지 대강은 이해할 수 있도록 도와주는 수준이 되었다.
이러한 발전의 결과로, 이 분야에 상업적인 관심이 쏟아지고 있다.
논문은 단기적인 관점에서는 데이터와 계산 능력의 증가, 머신러닝 기술의 발전을 감안했을 때 NLP 분야에 지속적인 성능 향상이 있을 것으로 예상한다. 그러나 장기적 관점에서는 언어학 분야에서 새로운 발견이 필요하다고 보고 있다.
논문의 마지막 부분을 읽고 얀 르쿤이 GPT-3에 내린 평가에 대한 기사가 떠올랐다. GPT-3를 헬스케어 분야에 적용했을 때 나타난 문제에 대한 기사였는데, 아직 갈 길이 멀다는 생각이 들었다. 정말로 NLP라는 분야가 한차원 높이 발전하기 위해서는, 언어학이라는 분야에서 새로운 관점의 탄생이 필요할지도 모르겠다.